VAE(Variational Autoencoder)에 대해 설명해 드릴게요.

학습 계획
- VAE란 무엇인가요?
- 오토인코더(Autoencoder)의 기본 개념
- VAE의 등장 배경 및 목표
- VAE의 핵심 구성 요소
- 인코더(Encoder): 데이터를 잠재 공간으로 압축
- 샘플러(Sampler): 잠재 공간에서 새로운 벡터 생성
- 디코더(Decoder): 잠재 벡터로 원본 데이터 복원
- VAE의 작동 원리
- 잠재 공간(Latent Space)의 중요성
- 재매개변수화 트릭(Reparameterization Trick)
- 손실 함수(Loss Function): 재구성 손실 + KL 발산
- VAE의 장점 및 활용 분야
- 간단한 VAE 구현 (Google Colab용 Python 코드)
- 데이터셋 준비
- 모델 아키텍처 정의
- 학습 과정
- 결과 시각화
1. VAE란 무엇인가요?
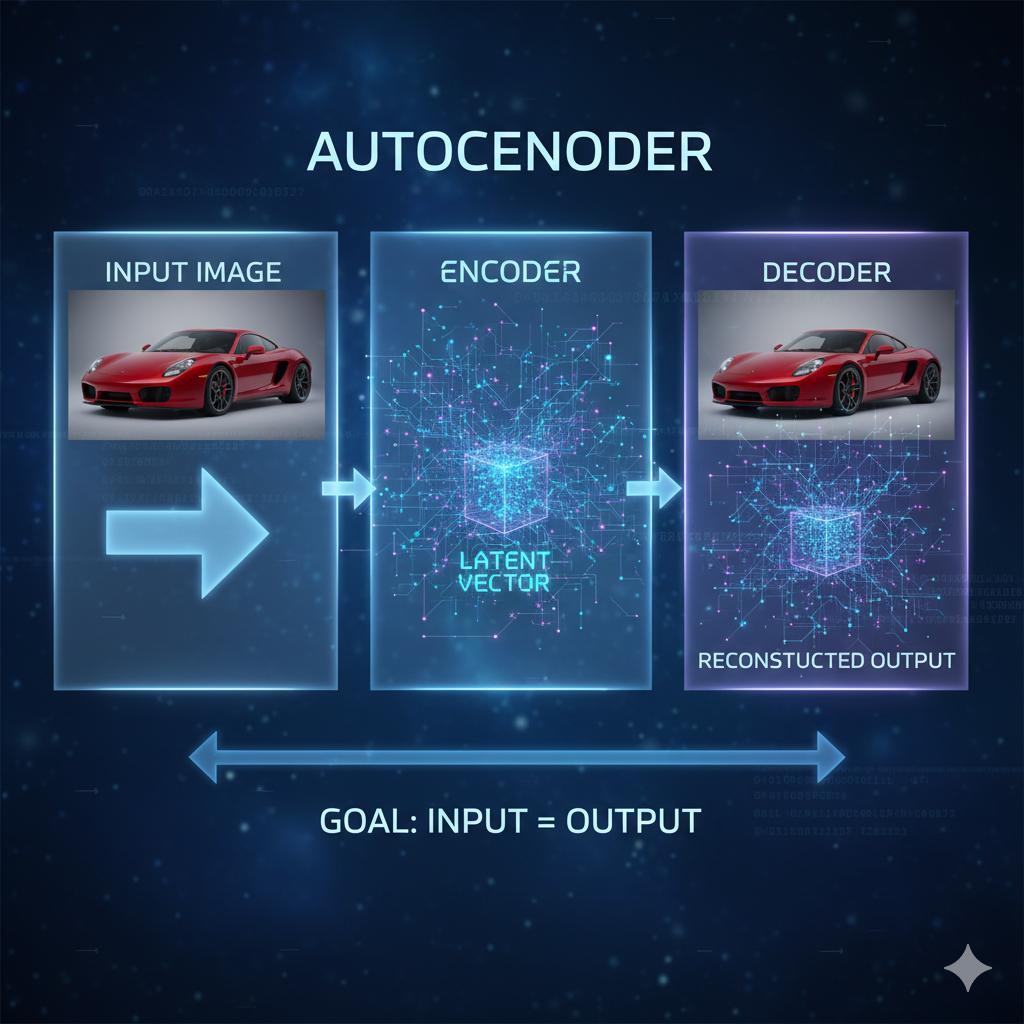
오토인코더(Autoencoder)의 기본 개념
먼저 VAE를 이해하기 위해 오토인코더(Autoencoder)부터 알아볼까요? 오토인코더는 입력 데이터를 압축했다가 다시 복원하는 신경망입니다. 마치 정보를 요약했다가 다시 풀어내는 것과 같아요.
예를 들어, 이미지를 '핵심 특징'만 남기고 압축했다가, 그 '핵심 특징'으로 다시 원본 이미지를 복원하는 식입니다. 여기서 '핵심 특징'이 바로 잠재 벡터(Latent Vector)라고 부르는 것입니다.
VAE의 등장 배경 및 목표
일반적인 오토인코더는 데이터 압축 및 복원에는 뛰어나지만, 잠재 공간(Latent Space)이 불연속적이고 구조화되어 있지 않은 경우가 많습니다. 즉, 잠재 벡터를 임의로 뽑아서 디코딩하면 의미 없는 결과가 나올 확률이 높습니다.
VAE는 이러한 문제를 해결하고, 잠재 공간을 "잘 구조화"하여 새로운 데이터를 생성할 수 있도록 설계되었습니다. VAE의 목표는 단순히 데이터를 압축하고 복원하는 것을 넘어, 잠재 공간에서 의미 있는 특징을 학습하고, 이 잠재 공간을 탐색하여 새로운 데이터를 생성하는 것입니다.
2. VAE의 핵심 구성 요소
VAE는 크게 세 가지 구성 요소로 이루어져 있습니다.
- 인코더(Encoder): 입력 데이터를 잠재 공간의 확률 분포(평균과 분산)로 변환합니다.
- 샘플러(Sampler): 인코더가 생성한 확률 분포에서 잠재 벡터를 샘플링합니다.
- 디코더(Decoder): 샘플링된 잠재 벡터를 받아 원본 데이터와 유사한 새로운 데이터를 생성합니다.

3. VAE의 작동 원리
잠재 공간(Latent Space)의 중요성
VAE에서 가장 중요한 개념 중 하나는 잠재 공간입니다. 잠재 공간은 데이터의 특징들이 압축되어 표현되는 저차원 공간입니다. VAE는 이 잠재 공간을 연속적이고 부드럽게(smooth) 만들어서, 잠재 벡터들 사이를 이동하면서 의미 있는 데이터 변화를 생성할 수 있도록 학습합니다.
예를 들어, 숫자 '0'의 이미지들이 잠재 공간의 한 영역에 모여 있고, 숫자 '1'의 이미지들이 다른 영역에 모여 있다면, 이 두 영역 사이를 부드럽게 이동하면 '0'에서 '1'로 점진적으로 변하는 이미지를 생성할 수 있습니다.

재매개변수화 트릭(Reparameterization Trick)
VAE는 인코더에서 잠재 벡터 z를 직접 예측하는 대신, 잠재 공간의 평균()과 분산()을 예측합니다. 그리고 이 평균과 분산을 이용해 샘플링 과정을 거쳐 z를 생성합니다.
여기서 문제가 발생하는데, 샘플링 과정은 미분 불가능합니다. 신경망을 학습시키려면 역전파(backpropagation)를 통해 미분값을 계산해야 하는데, 미분 불가능하면 학습을 시킬 수 없습니다.
이 문제를 해결하기 위해 재매개변수화 트릭을 사용합니다. 잠재 벡터 z를 다음과 같이 표현합니다.
여기서 (엡실론)은 평균이 0이고 분산이 1인 표준 정규 분포에서 샘플링된 값입니다. 이렇게 하면 샘플링 과정이 으로 이동하고, 와 는 신경망을 통해 직접 예측되기 때문에 미분이 가능해집니다.

손실 함수(Loss Function): 재구성 손실 + KL 발산
VAE는 두 가지 주요 손실 함수를 사용하여 학습됩니다.
- 재구성 손실 (Reconstruction Loss):
- 입력 데이터와 디코더가 생성한 데이터 간의 차이를 측정합니다. 이 손실은 VAE가 원본 데이터를 얼마나 잘 복원하는지를 나타냅니다. (예: MSE, Binary Cross-Entropy)
- KL 발산 (Kullback-Leibler Divergence) 손실:
- 인코더가 출력하는 잠재 분포()가 우리가 원하는 사전 분포(prior distribution, 보통 표준 정규 분포 )와 얼마나 다른지를 측정합니다. 이 손실은 잠재 공간을 부드럽게(smooth) 만들고, 의미 있는 샘플링을 가능하게 합니다.
이 두 손실의 합이 VAE의 최종 손실 함수가 됩니다.

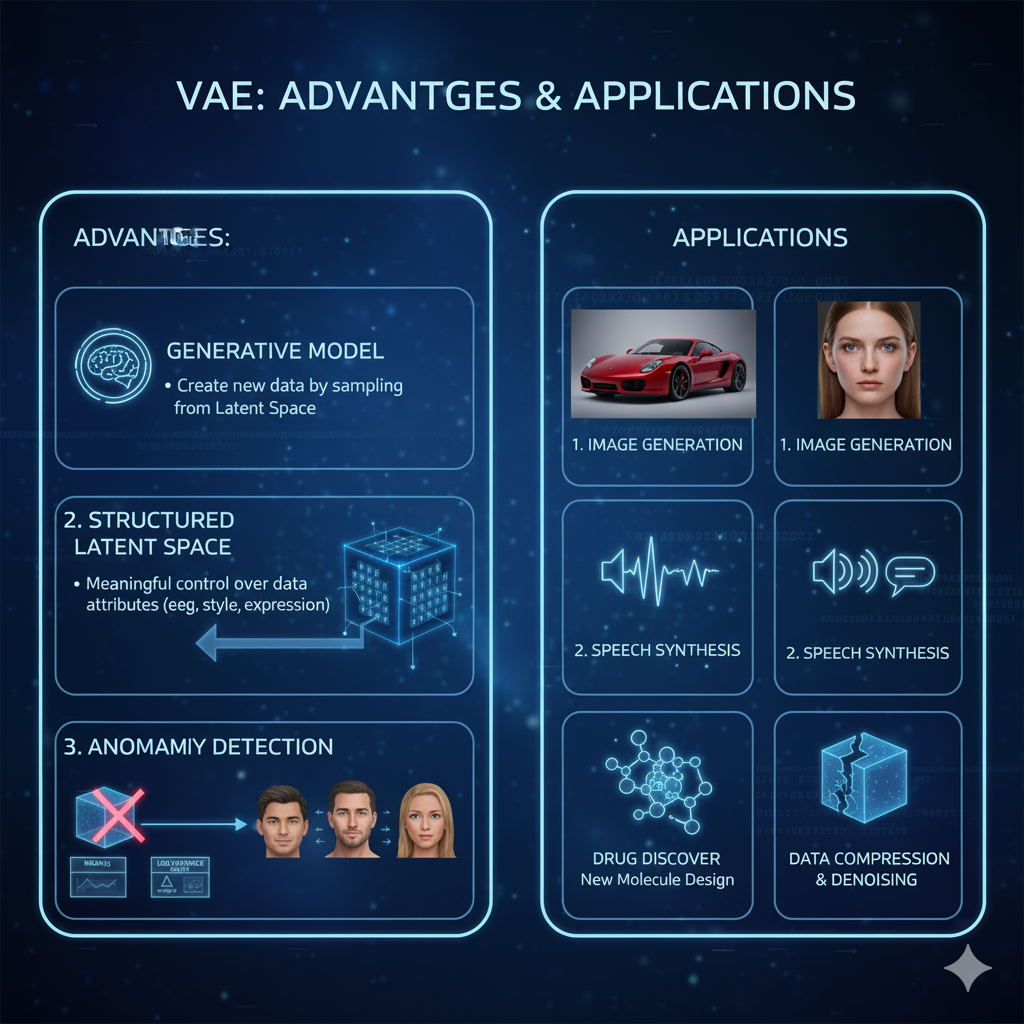
4. VAE의 장점 및 활용 분야
VAE는 다음과 같은 장점과 활용 분야를 가집니다.
장점:
- 새로운 데이터 생성: 잠재 공간에서 샘플링하여 훈련 데이터와 유사하지만 새로운 데이터를 생성할 수 있습니다.
- 의미 있는 잠재 공간: 잠재 공간이 구조화되어 있어, 잠재 벡터를 조작하여 데이터의 특정 속성을 제어하거나 변화를 관찰할 수 있습니다.
- 이상 감지(Anomaly Detection): 재구성 오류가 큰 데이터는 이상치로 간주할 수 있습니다.
활용 분야:
- 이미지 생성: 얼굴, 풍경, 스타일 등 다양한 이미지 생성
- 음성 합성: 새로운 음성 샘플 생성
- 텍스트 생성: 문장이나 문서 생성
- 약물 발견: 새로운 분자 구조 생성 및 탐색
- 데이터 압축 및 노이즈 제거
5. 예제코드 (Python)
# -----------------------------------------------------------
# VAE (Variational Autoencoder) on MNIST using TensorFlow/Keras
# This code is designed to be run on Google Colab.
# -----------------------------------------------------------
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
# --- 1. Load and Preprocess Data ---
print("1. Loading and Preprocessing MNIST Dataset...")
(x_train, _), (x_test, _) = keras.datasets.mnist.load_data()
# Normalize pixel values to [0, 1] and reshape to (num_samples, 28, 28, 1)
mnist_digits = np.concatenate([x_train, x_test], axis=0)
mnist_digits = np.expand_dims(mnist_digits, -1).astype("float32") / 255
print(f"Dataset shape: {mnist_digits.shape}")
print("-" * 50)
# --- 2. Define VAE Model Architecture ---
print("2. Defining VAE Model Architecture...")
# Configuration
latent_dim = 2 # Dimension of the latent space (for easy visualization)
image_size = (28, 28, 1)
# --- Encoder ---
encoder_inputs = keras.Input(shape=image_size)
x = layers.Conv2D(32, 3, activation="relu", strides=2, padding="same")(encoder_inputs)
x = layers.Conv2D(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Flatten()(x)
x = layers.Dense(16, activation="relu")(x)
z_mean = layers.Dense(latent_dim, name="z_mean")(x)
z_log_var = layers.Dense(latent_dim, name="z_log_var")(x)
# Custom sampling layer
class Sampling(layers.Layer):
"""Uses (z_mean, z_log_var) to sample z, the vector encoding a digit."""
def call(self, inputs):
z_mean, z_log_var = inputs
epsilon = tf.keras.backend.random_normal(shape=tf.shape(z_mean))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
z = Sampling()([z_mean, z_log_var])
encoder = keras.Model(encoder_inputs, [z_mean, z_log_var, z], name="encoder")
print("Encoder Summary:")
encoder.summary()
# --- Decoder ---
latent_inputs = keras.Input(shape=(latent_dim,))
x = layers.Dense(7 * 7 * 64, activation="relu")(latent_inputs)
x = layers.Reshape((7, 7, 64))(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Conv2DTranspose(32, 3, activation="relu", strides=2, padding="same")(x)
decoder_outputs = layers.Conv2DTranspose(1, 3, activation="sigmoid", padding="same")(x)
decoder = keras.Model(latent_inputs, decoder_outputs, name="decoder")
print("\nDecoder Summary:")
decoder.summary()
# --- VAE Model ---
class VAE(keras.Model):
def __init__(self, encoder, decoder, **kwargs):
super(VAE, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
self.total_loss_tracker = keras.metrics.Mean(name="total_loss")
self.reconstruction_loss_tracker = keras.metrics.Mean(name="reconstruction_loss")
self.kl_loss_tracker = keras.metrics.Mean(name="kl_loss")
@property
def metrics(self):
return [
self.total_loss_tracker,
self.reconstruction_loss_tracker,
self.kl_loss_tracker,
]
def train_step(self, data):
with tf.GradientTape() as tape:
z_mean, z_log_var, z = self.encoder(data)
reconstruction = self.decoder(z)
# Reconstruction loss (Binary Cross-Entropy for pixel values 0-1)
reconstruction_loss = tf.reduce_mean(
tf.reduce_sum(
keras.losses.binary_crossentropy(data, reconstruction), axis=(1, 2)
)
)
# KL Divergence loss (encourages latent distribution to be close to N(0,1))
kl_loss = -0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
kl_loss = tf.reduce_mean(tf.reduce_sum(kl_loss, axis=1))
total_loss = reconstruction_loss + kl_loss
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
self.total_loss_tracker.update_state(total_loss)
self.reconstruction_loss_tracker.update_state(reconstruction_loss)
self.kl_loss_tracker.update_state(kl_loss)
return {
"loss": self.total_loss_tracker.result(),
"reconstruction_loss": self.reconstruction_loss_tracker.result(),
"kl_loss": self.kl_loss_tracker.result(),
}
print("\nVAE Model defined.")
print("-" * 50)
# --- 3. Compile and Train VAE ---
print("3. Compiling and Training VAE...")
vae = VAE(encoder, decoder)
vae.compile(optimizer=keras.optimizers.Adam())
history = vae.fit(mnist_digits, epochs=10, batch_size=128) # Train for 10 epochs (can increase for better results)
print("\nVAE Training Complete.")
print("-" * 50)
# --- 4. Visualize Results ---
print("4. Visualizing Results...")
# Function to plot generated digits
def plot_latent_space(vae, n=30, figsize=15):
# display a n*n 2D manifold of digits
digit_size = 28
scale = 1.0
figure = np.zeros((digit_size * n, digit_size * n))
# Linearly spaced coordinates corresponding to the 2D plot of digit classes in the latent space
grid_x = np.linspace(-scale, scale, n)
grid_y = np.linspace(-scale, scale, n)[::-1]
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z_sample = np.array([[xi, yi]])
x_decoded = vae.decoder.predict(z_sample)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[
i * digit_size : (i + 1) * digit_size,
j * digit_size : (j + 1) * digit_size,
] = digit
plt.figure(figsize=(figsize, figsize))
start_range = digit_size // 2
# end_range = n * digit_size + start_range + 1 # Original calculation
end_range = n * digit_size # Adjusted calculation to match the number of labels
pixel_range = np.arange(start_range, end_range, digit_size)
sample_range_x = np.round(grid_x, 1)
sample_range_y = np.round(grid_y, 1)
plt.xticks(pixel_range, sample_range_x)
plt.yticks(pixel_range, sample_range_y)
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.imshow(figure, cmap="Greys_r")
plt.title("2D Latent Space Manifold")
plt.show()
plot_latent_space(vae)
# Function to plot original vs. reconstructed images
def plot_reconstructions(vae, data, n_images=10):
_, _, z = vae.encoder.predict(data[:n_images])
reconstructions = vae.decoder.predict(z)
plt.figure(figsize=(2 * n_images, 4))
for i in range(n_images):
# Original image
ax = plt.subplot(2, n_images, i + 1)
plt.imshow(data[i].reshape(28, 28), cmap="Greys_r")
plt.title("Original")
plt.axis("off")
# Reconstructed image
ax = plt.subplot(2, n_images, i + 1 + n_images)
plt.imshow(reconstructions[i].reshape(28, 28), cmap="Greys_r")
plt.title("Reconstructed")
plt.axis("off")
plt.suptitle("Original vs. Reconstructed Images")
plt.show()
# Use test data for reconstruction visualization
plot_reconstructions(vae, mnist_digits[len(x_train):])
print("\nVisualization complete. You can see the smooth transitions in the latent space and how well the VAE reconstructs digits!")
print("-" * 50)'AI' 카테고리의 다른 글
| [AI 테스트] 블랙박스 테스팅 기법 (0) | 2026.03.01 |
|---|---|
| Agentic AI (3) | 2025.09.20 |
| [AI 테스트] 커버리지 테스트 기법 (Coverage Testing) (6) | 2025.08.31 |
| [AI 테스트] 메타모픽 테스트 기법 (Metamorphic Testing) (2) | 2025.08.31 |
| MCP (Model Context Protocol) (4) | 2025.08.25 |