LangChain은 대규모 언어 모델(LLM)을 기반으로 애플리케이션을 개발할 때 필요한 기능들을 조립하기 쉽게 만들어둔 오픈소스 프레임워크입니다. 단순히 LLM에 질문을 던지고 답변을 받는 것을 넘어, 외부 데이터를 결합하거나 특정 도구를 사용하게 함으로써 LLM의 근본적인 한계(최신 정보 부족, 할루시네이션, 단순 텍스트 생성에 국한됨)를 극복하도록 돕습니다.
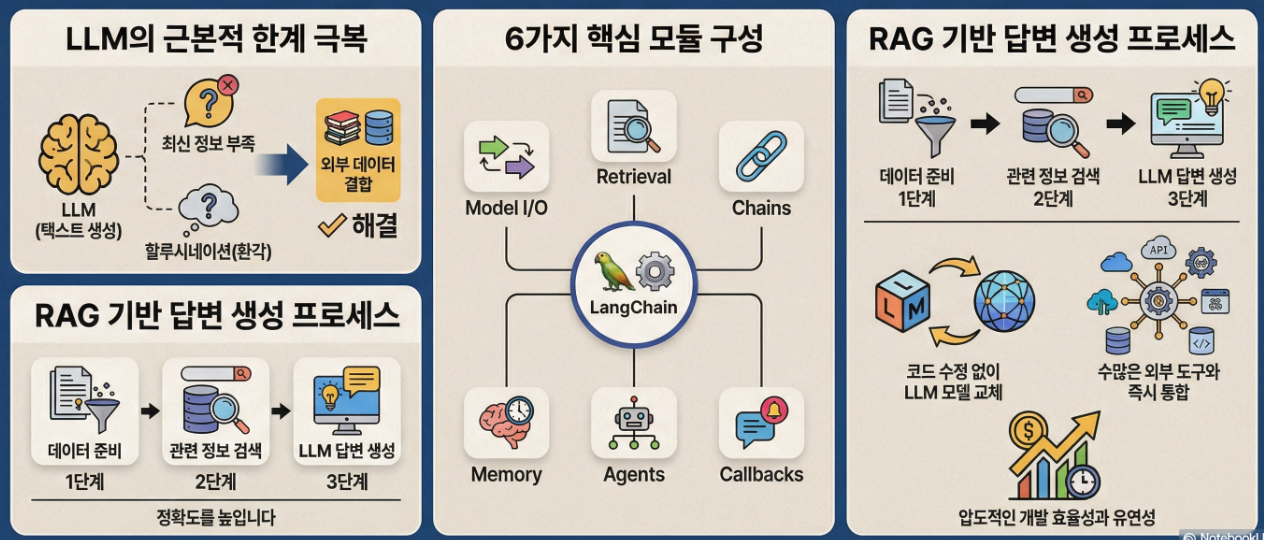
1. LangChain의 핵심 구성 요소 (Core Components)
복잡한 개념을 시각적으로 파악하기 위해 랭체인을 이루는 6가지 주요 모듈을 표로 구조화했습니다.
| 구성 요소 (Module) | 핵심 역할 | 구체적인 활용 예시 |
| Model I/O (모델 입출력) |
다양한 LLM(Gemini, OpenAI 등)과의 표준화된 통신 인터페이스 및 프롬프트 관리 | 사용자 입력값을 프롬프트 템플릿에 주입하고, LLM의 응답을 JSON 형태로 파싱하여 반환 |
| Retrieval (데이터 검색) |
외부 데이터(PDF, 웹페이지, 사내 DB)를 불러와 LLM이 읽을 수 있도록 변환하고 검색 | PDF 문서를 로드하고 쪼개어 Vector DB에 저장한 뒤, 사용자 질문과 가장 유사한 단락을 찾아 LLM에 제공 (RAG) |
| Chains (체인) |
여러 단계의 작업(프롬프트 구성 → 모델 호출 → 출력 파싱)을 하나의 파이프라인으로 연결 | 요약용 체인과 번역용 체인을 연결하여, 긴 영문 문서를 한국어로 요약해 주는 단일 파이프라인 구축 |
| Memory (메모리) |
이전 대화 기록을 저장하고 관리하여 연속적인 문맥(Context)을 유지 | 챗봇이 사용자의 이전 질문("내 이름은 홍길동이야")을 기억하고 다음 답변("홍길동님, 무엇을 도와드릴까요?")에 활용 |
| Agents (에이전트) |
LLM이 스스로 판단하여 주어진 도구(Tools) 중 어떤 것을, 어떤 순서로 사용할지 결정 | "현재 서울 날씨에 맞춰 옷차림을 추천해 줘"라는 질문에 웹 검색 도구를 실행해 날씨를 확인한 후 답변 생성 |
| Callbacks (콜백) |
체인이나 에이전트가 실행되는 중간 과정을 로깅, 모니터링, 스트리밍 | 사용자가 기다리지 않도록 LLM이 단어를 생성할 때마다 화면에 실시간으로 출력(Streaming) |

2. LangChain의 작동 원리 (RAG 아키텍처 예시)
최근 랭체인이 가장 많이 활용되는 분야는 RAG(Retrieval-Augmented Generation, 검색 증강 생성) 방식의 사내 챗봇 구축입니다. 랭체인을 활용한 작동 원리는 다음과 같은 단계로 이루어집니다.
- 1단계: 데이터 준비 (Data Ingestion)
- 회사 규정집(PDF)을 Document Loaders로 불러옵니다.
- Text Splitters를 사용해 문서를 수백 글자 단위의 청크(Chunk)로 잘게 쪼갭니다.
- 임베딩 모델을 통해 텍스트를 숫자로 된 벡터(Vector)로 변환하여 Vector Store(벡터 DB)에 저장합니다.

- 2단계: 사용자 질의 처리 (Querying & Retrieval)
- 사용자가 "휴가 신청은 어떻게 해?"라고 질문합니다.
- Retriever가 질문을 벡터로 변환한 뒤, 벡터 DB에서 가장 유사한 '휴가 관련 규정' 텍스트 조각을 검색해 가져옵니다.
- 3단계: 답변 생성 (Generation with Chain)
- Prompt Template에 사용자의 질문과 방금 검색해 온 규정 텍스트를 함께 결합합니다.
- 결합된 프롬프트를 LLM에 전달하면, LLM은 해당 규정에 기반하여 정확한 답변을 생성합니다.

3. LangChain 활용 시 고려사항 및 한계점
랭체인은 강력한 도구이지만, 아키텍처 설계 시 다음 사항을 균형 있게 고려해야 합니다.
- 장점 (효율성과 유연성): LLM 종류(OpenAI, Google 등)를 코드를 거의 수정하지 않고 쉽게 교체할 수 있습니다. 수많은 외부 도구 및 데이터베이스와의 통합(Integration)이 이미 구현되어 있어 개발 속도가 비약적으로 상승합니다.
- 단점 (추상화의 비용): 프레임워크가 고도로 추상화되어 있어, 내부에서 어떤 프롬프트가 오가는지 직관적으로 디버깅하기 어려울 때가 있습니다. 또한 라이브러리 업데이트가 매우 잦아 기존 코드가 구버전(Deprecated)이 되는 속도가 빠릅니다.

'딥러닝' 카테고리의 다른 글
| [머신러닝] 앙상블기법 : Bagging vs. Boosting (0) | 2026.03.22 |
|---|---|
| 트랜스포머(Transformer) (0) | 2026.02.19 |
| 경사하강법 고급 최적화 알고리즘(Optimizer) (0) | 2026.02.19 |
| 고급 경사하강법 (BGS, SGD, MSGD) (0) | 2026.02.18 |
| 경사하강법 (Gradient Descent) (0) | 2026.02.18 |